
pip install selenium
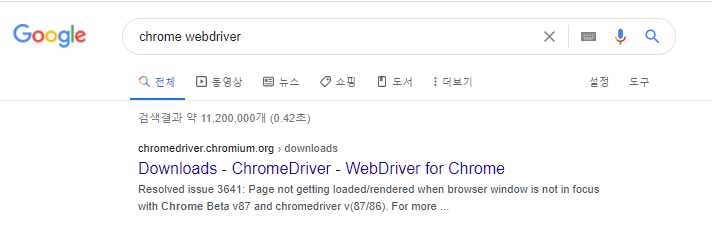
chrome webdriver를 검색합니다

자신의 크롬 정보를 확인합니다 저는 87.0.4280.~ 입니다
(참고로 웹페이지에서 우측상단에 설정-도움말-크롬정보 경로입니다)
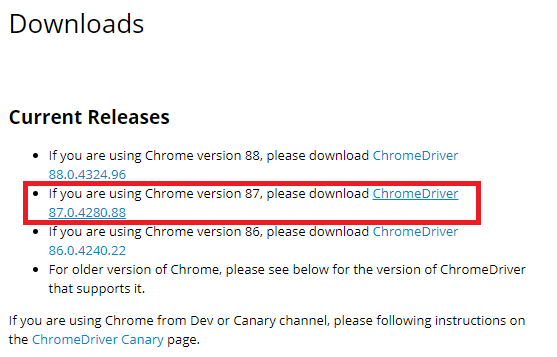

64비트가 없어서 윈도우는 32비트로 다운받았습니다.

10번째 driver을 driver로 수정해주세요

실행창에서 python b.py 입력
( 현재 파일은 D드라이브-test 폴더안에 있으니 경로를 test폴더로 꼭 이동해서 해야합니다)

상품평의 경로를 가져옵니다
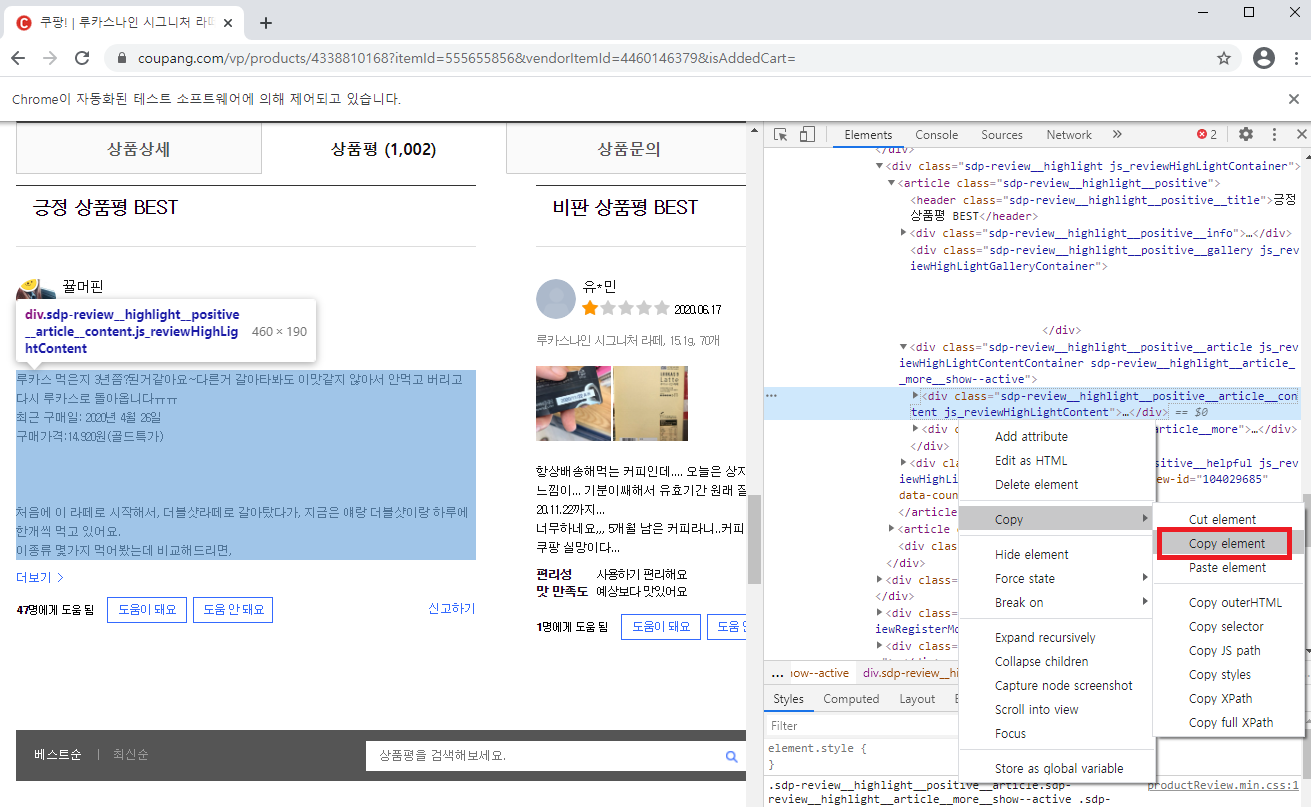
copy xpath-copy 복사 해주세요
copy -copy element를 이용해서 댓글 정보 수집

26번째는 클래스 부분만 필요하니 클래스부분정보만 추출하고 나머지는 다 버린다.

전체 코드
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome("./chromedriver.exe")
driver.get("https://www.coupang.com/vp/products/4338810168?itemId=555655856&vendorItemId=4460146379&isAddedCart=")
#페이지 읽어오기
time.sleep(5)
#5초 정도 후에 클릭해라 페이지 열리고 댓글로 이동
a=driver.find_element_by_xpath("//*[@id='btfTab']/ul[1]/li[2]")
#xpath 붙여넣기 [@id="btfTab"] ->[@id='btfTab']
a.click()
time.sleep(5)
#5초 정도 후에 찾을 댓글부분으로
html = driver.page_source
soup = BeautifulSoup(html,"html.parser")
res=soup.find_all(class_= "sdp-review__article__list__review__content js_reviewArticleContent")
#찾을 내용
for n in res:
print(n.get_text())




